DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models

|
|
|
We present DreamAvatar, a text-and-shape guided framework for generating high-quality 3D human avatars with controllable poses. While encouraging results have been produced by recent methods on text-guided 3D common object generation, generating high-quality human avatars remains an open challenge due to the complexity of the human body's shape, pose, and appearance. We propose DreamAvatar to tackle this challenge, which utilizes a trainable NeRF for predicting density and color features for 3D points and a pre-trained text-to-image diffusion model for providing 2D self-supervision. Specifically, we leverage SMPL models to provide rough pose and shape guidance for the generation. We introduce a dual space design that comprises a canonical space and an observation space, which are related by a learnable deformation field through the NeRF, allowing for the transfer of well-optimized texture and geometry from the canonical space to the target posed avatar. Additionally, we exploit a normal-consistency regularization to allow for more vivid generation with detailed geometry and texture. Through extensive evaluations, we demonstrate that DreamAvatar significantly outperforms existing methods, establishing a new state-of-the-art for text-and-shape guided 3D human generation.
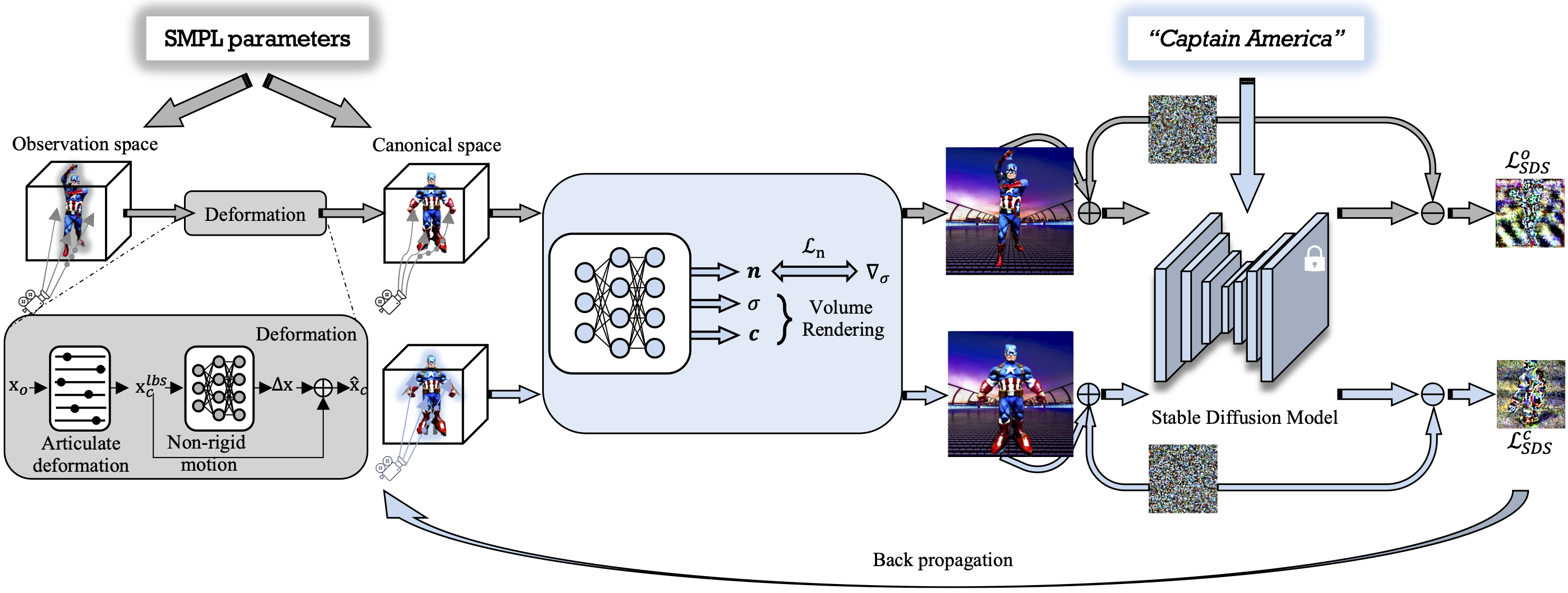
DreamAvatar takes as input a text prompt and SMPL parameters to optimize a trainable NeRF model via a pre-trained denoising stable diffusion model. At the core of our network are two modeling spaces that are related by an SMPL-based learnable deformation field, which robustly controls the pose and transfers the high-quality geometry and texture from the canonical space to the observation space..
Qualitative comparisons with TEXTure, AvatarCLIP and Latent-NeRF with rotated subjects. Please scroll down for full comparisons
DreamAvatar can maintain high-quality texture and geometry for extreme poses, e.g., self-occlusion pose and crouching, thanks to our dual space design.
DreamAvatar can generate faithful avatars fulfilling the text with additional descriptive information, e.g., specifying age, color, and body type.
DreamAvatar can generate different size of 3D human avatars, \eg, thin, short, tall, fat, by editing the SMPL shape parameters.
@article{cao2023dreamavatar,
title={Dreamavatar: Text-and-shape guided 3d human avatar generation via diffusion models},
author={Cao, Yukang and Cao, Yan-Pei and Han, Kai and Shan, Ying and Wong, Kwan-Yee K},
journal={arXiv preprint arXiv:2304.00916},
year={2023}
}
Webpage template borrowed from DreamBooth3D, 2023 by Amit Raj.