Abstract
We present DreamAvatar, a text-and-shape guided framework for generating high-quality 3D human avatars with controllable poses. While encouraging results have been reported by recent methods on text-guided 3D common object generation, generating high-quality human avatars remains an open challenge due to the complexity of the human body's shape, pose, and appearance. We propose DreamAvatar to tackle this challenge, which utilizes a trainable NeRF for predicting density and color for 3D points and pretrained text-to-image diffusion models for providing 2D self-supervision. Specifically, we leverage the SMPL model to provide shape and pose guidance for the generation. We introduce a dual-observation-space design that involves the joint optimization of a canonical space and a posed space that are related by a learnable deformation field. This facilitates the generation of more complete textures and geometry faithful to the target pose. We also jointly optimize the losses computed from the full body and from the zoomed-in 3D head to alleviate the common multi-face ``Janus'' problem and improve facial details in the generated avatars. Extensive evaluations demonstrate that DreamAvatar significantly outperforms existing methods, establishing a new state-of-the-art for text-and-shape guided 3D human avatar generation.
3D Human Avatar Generation - Canonical Pose
DreamAvatar can generate a diverse set of 3D human avatars, e.g., real-world human beings, movie, anime, and video game characters, etc.
| Wonder Woman | Crystal Maiden as in Dota2 | Woody in the Toy Story | I am Groot |
| Electro from Marvel | Spiderman | Alien | Joker |
| Flash from DC | C-3PO from Star Wars | Luffy from One Piece | Hatake Kakashi |
| Link from Zelda | Hipster man | Clown | Uchiha Sasuke |
| A woman in a hippie outfit | Buddhist Monk | Track and field athlete | Body builder wearing a tanktop |
3D Human Avatar Generation - Controllable Poses
In addition to static 3D human avatar generations under canonical space, our method can create 3D human avatars under various poses and maintain high-quality texture and geometry from extreme poses, e.g., complex poses with severe self-occlusion.
| I am Groot | |||
| Joker | |||
| Flash from DC | Spiderman | ||
3D Human Avatar Generation - Controllable Shapes
Our method can also generate different sizes of 3D human avatars, e.g., thin, short, tall, fat by modifying the SMPL shape parameters.
| I am Groot | |||
3D Human Avatar Generation - Text Manipulation
By editing the textual prompt, DreamAvatar has the capability of generating faithful avatars that accurately embody the provided text, incorporating additional descriptive information and capturing the unique characteristics of the main subject.
| Joker wearing a green suit | Joker wearing a texudo | Joker wearing a pink suit | Joker wearing a black suit |
3D Human Avatar Generation - Attributes Integration (head & body)
Benefiting from the joint modeling of the zoomed-in 3D head and full body, our method seamlessly integrates the unique attributes derived from both head and body characters. See visualizations in Fig. 8. In contrast to the conventional approach of separately modeling head and body parts, DreamAvatar harmoniously combines these elements, resulting in a cohesive model that faithfully captures the essence of both subjects.
| Clown | Deadpool | Joker | Clown |
| dreassing the clothes of Woody | dressing Joker-style's coat | dressed like Star-Lord | wearing the clothes of Link |
Method
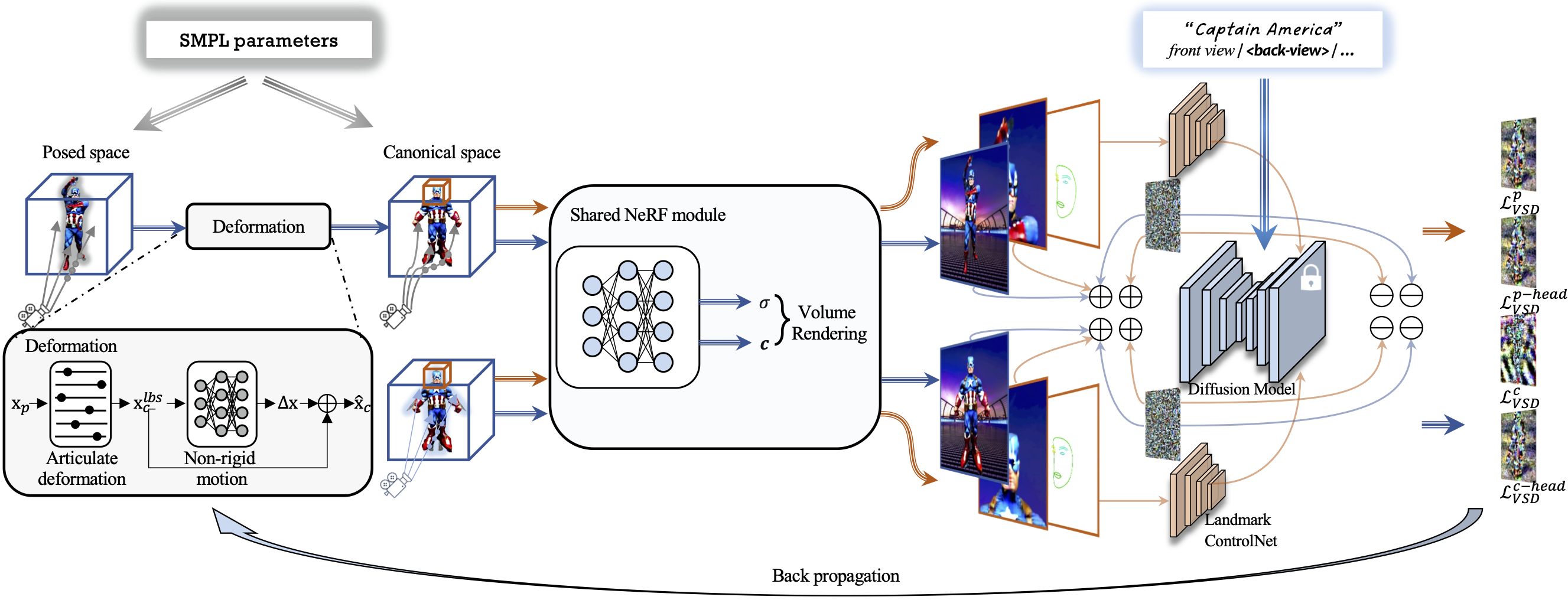
Our network takes as input a text prompt and SMPL parameters to optimize a trainable NeRF via a pretrained denoising stable diffusion model. At the core of our network are two observation spaces, namely the canonical space and the posed space, that are related by an SMPL-based learnable deformation field. This dual-observation-space design facilities the generation of more complete textures and geometry faithful to the target pose.